ELK Architecture : Shards, ILM et Query DSL expliqués simplement
Temps de lecture : 14 min | Niveau : Intermédiaire | Mis à jour : Février 2026
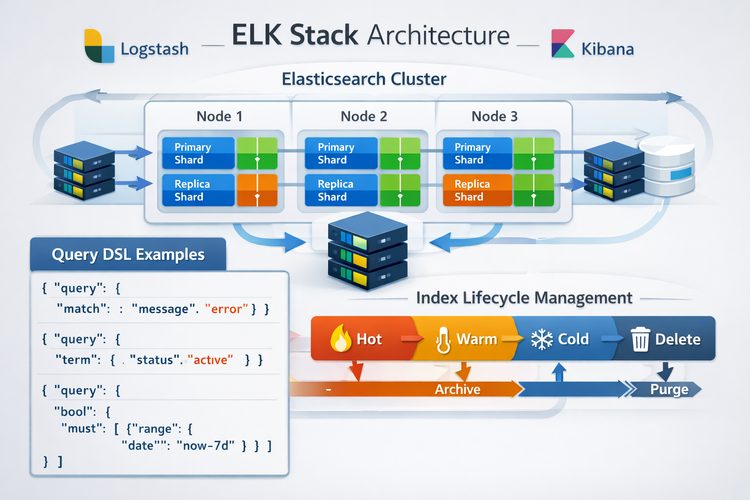
L'essentiel : L'architecture d'Elasticsearch repose sur trois piliers que tout utilisateur de la stack ELK doit comprendre. Les shards découpent vos index en fragments distribués sur plusieurs nœuds pour la performance et la résilience. L'ILM (Index Lifecycle Management) automatise le cycle de vie de vos données : hot → warm → cold → delete. Le Query DSL est le langage JSON qui vous permet d'interroger Elasticsearch avec précision. Ce guide explique ces trois concepts avec des exemples concrets et du code prêt à utiliser.
Vous avez installé la stack ELK, vos logs arrivent dans Elasticsearch et Kibana affiche des dashboards. Mais dès que le volume de données augmente, des questions se posent : pourquoi mon cluster ralentit ? Comment gérer la rétention des anciens index ? Comment écrire des requêtes efficaces ?
La réponse se trouve dans l'architecture interne d'Elasticsearch. Ce guide vous explique les trois mécanismes essentiels que tout ingénieur DevOps, administrateur système ou développeur doit maîtriser pour exploiter ELK en production.
Besoin d'un rappel sur les fondamentaux ? Consultez d'abord notre guide complet ELK : Elasticsearch, Logstash & Kibana
ILM : automatiser le cycle de vie des index
En production, les index de logs grossissent continuellement. Sans gestion automatisée, le cluster finit par manquer d'espace disque et les performances se dégradent. L'Index Lifecycle Management (ILM) résout ce problème en automatisant la gestion de vos index à travers 5 phases.
Les 5 phases du cycle de vie
| Phase | Description | Actions typiques | Type de disque |
|---|---|---|---|
| Hot | L'index est en cours d'écriture et fréquemment interrogé | Rollover (créer un nouvel index quand le seuil est atteint) | SSD rapide |
| Warm | L'index n'est plus écrit mais encore consulté régulièrement | Shrink (réduire les shards), Force merge (optimiser les segments) | SSD standard |
| Cold | L'index est rarement consulté, mais doit rester accessible | Réduction des replicas, searchable snapshots | HDD / stockage économique |
| Frozen | L'index est quasi jamais consulté, tolérance aux requêtes lentes | Searchable snapshots depuis stockage froid | Stockage objet (S3, etc.) |
| Delete | L'index est supprimé définitivement | Suppression de l'index et de ses données | — |
Analogie : pensez au tri de vos emails. Les emails récents (hot) restent dans votre boîte de réception. Les emails de la semaine dernière (warm) vont dans un dossier. Les anciens emails (cold) sont archivés. Et au bout de 2 ans (delete), vous les supprimez. ILM fait exactement ça, automatiquement.
Pourquoi ILM est indispensable en production
Sans ILM, vous devez gérer manuellement la rotation et la suppression de vos index. Avec un flux de logs continu, cela devient vite ingérable. ILM vérifie automatiquement (toutes les 10 minutes par défaut) si un index doit passer à la phase suivante, en fonction de critères que vous définissez : âge de l'index, taille des shards ou nombre de documents.
Configurer une politique ILM : exemple complet
Voici un exemple réaliste de politique ILM pour des logs applicatifs. L'objectif : conserver les logs récents sur du stockage rapide, les archiver après 7 jours, et les supprimer après 90 jours.
PUT _ilm/policy/logs-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_primary_shard_size": "50gb",
"max_age": "1d"
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"shrink": {
"number_of_shards": 1
},
"forcemerge": {
"max_num_segments": 1
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"allocate": {
"number_of_replicas": 0
}
}
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}Ce que fait cette politique :
- Hot : un nouvel index est créé (rollover) quand le shard dépasse 50 Go ou quand l'index a 1 jour
- Warm (après 7 jours) : l'index est compacté en 1 seul shard et les segments Lucene sont fusionnés pour optimiser l'espace
- Cold (après 30 jours) : les replicas sont supprimés pour économiser de l'espace disque
- Delete (après 90 jours) : l'index est définitivement supprimé
Pour appliquer cette politique à un index template :
PUT _index_template/logs-template
{
"index_patterns": ["logs-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "logs-policy"
}
}
}Tous les index dont le nom commence par "logs-" seront automatiquement gérés par cette politique ILM.
Query DSL : le langage de requêtes d'Elasticsearch
Le Query DSL (Domain Specific Language) est le langage JSON utilisé pour interroger Elasticsearch. C'est l'équivalent du SQL pour les bases de données relationnelles, mais adapté à la recherche full-text et aux agrégations sur des données distribuées.
Query context vs Filter context
Elasticsearch distingue deux contextes d'exécution pour les requêtes. Comprendre cette distinction est essentiel pour écrire des requêtes performantes :
| Contexte | Question posée | Score de pertinence ? | Mise en cache ? | Performance |
|---|---|---|---|---|
| Query | « À quel point ce document correspond-il à la requête ? » | Oui (calcul du _score) | Non | Plus lent |
| Filter | « Ce document correspond-il, oui ou non ? » | Non (binaire) | Oui (automatique) | Plus rapide |
Règle d'or : utilisez des filters pour les critères exacts (statut, date, ID) et des queries pour la recherche textuelle où la pertinence compte. Les filters sont cachés automatiquement par Elasticsearch et consomment moins de CPU.
Les types de requêtes essentiels
| Requête | Usage | Exemple |
|---|---|---|
match |
Recherche full-text (avec analyse du texte) | Trouver les logs contenant "connection timeout" |
term |
Correspondance exacte (sans analyse) | Filtrer par status code "500" |
range |
Plage de valeurs (dates, nombres) | Logs des 24 dernières heures |
bool |
Combiner plusieurs critères (must, should, must_not, filter) | Erreurs 500 sur le service "api" cette semaine |
match_phrase |
Recherche d'une expression exacte dans l'ordre | Trouver "out of memory" |
wildcard |
Recherche avec jokers (* et ?) | Trouver tous les champs commençant par "err*" |
exists |
Vérifier qu'un champ existe | Documents qui ont un champ "error_message" |
Exemples de requêtes courantes
1. Recherche full-text simple
Trouver tous les documents contenant "connection refused" dans le champ message :
GET logs-*/_search
{
"query": {
"match": {
"message": "connection refused"
}
}
}La requête match analyse le texte : elle cherche "connection" OU "refused". Pour une expression exacte, utilisez match_phrase.
2. Requête combinée avec bool
Trouver les erreurs 500 du service "api-gateway" survenues dans les dernières 24 heures :
GET logs-*/_search
{
"query": {
"bool": {
"must": [
{ "match": { "service": "api-gateway" } }
],
"filter": [
{ "term": { "status_code": 500 } },
{ "range": {
"@timestamp": {
"gte": "now-24h",
"lte": "now"
}
}
}
]
}
}
}Le must influence le score de pertinence. Le filter filtre sans calculer de score (plus performant). C'est la structure la plus utilisée en production.
3. Agrégation : top 5 des erreurs par service
Compter le nombre d'erreurs par service et afficher les 5 services avec le plus d'erreurs :
GET logs-*/_search
{
"size": 0,
"query": {
"term": { "level": "error" }
},
"aggs": {
"errors_par_service": {
"terms": {
"field": "service.keyword",
"size": 5
}
}
}
}"size": 0 signifie qu'on ne veut pas les documents eux-mêmes, uniquement le résultat de l'agrégation. Le champ .keyword est utilisé pour les termes exacts (non analysés).
4. Recherche avec date range et tri
Dernières 100 entrées de logs, triées par date décroissante :
GET logs-*/_search
{
"size": 100,
"sort": [
{ "@timestamp": { "order": "desc" } }
],
"query": {
"range": {
"@timestamp": {
"gte": "now-7d"
}
}
}
}
Astuce Kibana : vous n'avez pas besoin d'écrire du Query DSL à la main pour la plupart des cas d'usage. Kibana traduit automatiquement vos filtres en Query DSL. Mais comprendre le DSL vous permet de créer des requêtes avancées, de débugger les requêtes générées par Kibana et de les utiliser dans vos scripts d'automatisation.
Bonnes pratiques architecture ELK
| Domaine | Bonne pratique | Erreur fréquente |
|---|---|---|
| Shards | Viser 10-50 Go par shard, 1 primary shard par défaut | Mettre 5 shards sur un index de 1 Go (overhead inutile) |
| Replicas | Toujours au moins 1 replica en production | 0 replica = perte de données si un nœud tombe |
| ILM | Activer ILM dès le premier index. Définir une politique de rétention claire. | Laisser les index grandir sans limite et supprimer manuellement |
| Rollover | Utiliser le rollover automatique (ILM + data streams) | Créer un index par jour manuellement avec un cron |
| Requêtes | Utiliser filter pour les critères exacts, query pour le full-text |
Tout mettre dans must (calcul de score inutile) |
| Mapping | Définir un mapping explicite pour les champs importants | Se fier uniquement au mapping dynamique (types incorrects) |
| Cluster | Minimum 3 nœuds pour la haute disponibilité | Un seul nœud en production (single point of failure) |
Envie de maîtriser l'architecture ELK en profondeur ?
La formation ELK de Lenidit couvre les shards, ILM, Query DSL, Logstash, Kibana et le déploiement en production. Exercices pratiques inclus.
19€/mois pour cette formation et tout le catalogue (Docker, Kubernetes, CI/CD, cybersécurité). Attestation incluse.
Accéder à la formation ELK